This project was completed in cooperation with an active Oil & Gas Operator.
This is our first publication in a series of three successful pilots, and reports on recently completed work undertaken over the last two years. We’re excited to share the results of a live project with an active Oil and Gas operator. This pilot was executed in several licenses in the Neuquén basin of central Argentina. Biodentify applied and blind tested patented DNA fingerprinting technology and, using advanced machine learning algorithms, accurately predicted hydrocarbon presence in the subsurface prior to drilling.
The areas studied contained both conventional and unconventional fields. This project delivered proof of technology in the form of a highly accurate map of subsurface hydrocarbon presence, where productivity was predicted with 97% accuracy at 300 blinded sample locations. All results are based on real data from our own fieldwork.

Project background summary
In 2018, Biodentify was awarded a research grant by the EU Horizon 2020 fund. It was time for us to get visibility in the market and involve oil and gas operators with active drilling projects. We used the EU grant to set up research pilots in three different areas and through our operator, we were able to access a high producing shallow oil field and a field with deeper gas reserves.
We concentrated on sampling locations with known hydrocarbon presence, taking 1100 samples. For 800 of these samples, the hydrocarbon data remained known to us; used to train a machine learning model. 300 samples were relabeled and ‘blinded’ for us by the operator in order to be able to validate our predictions.
Our unique methodology
We began executing our research in an area of 40 by 50 km. A grid sampling method (~400-1,200 m spacing) is used, and as only shallow soil samples are required we covered this area relatively quickly with a field crew and car. In this pilot, we analyzed the soil taken for microbes in our German and Netherlands’ labs, separating the microbial DNA from the soil, ending up with a DNA fingerprint for each location.
This data is very vast, hundreds of millions of numerical values, too vast for us humans to make sense of it alone, which is where big data supercomputing power comes in.
The use of our unique and constantly updated DNA database, alongside big data algorithms, machine learning, and our own metagenomic pipeline, ensure that the model is constantly enhanced and improved over time to enable us to accurately predict subsurface hydrocarbon presence.
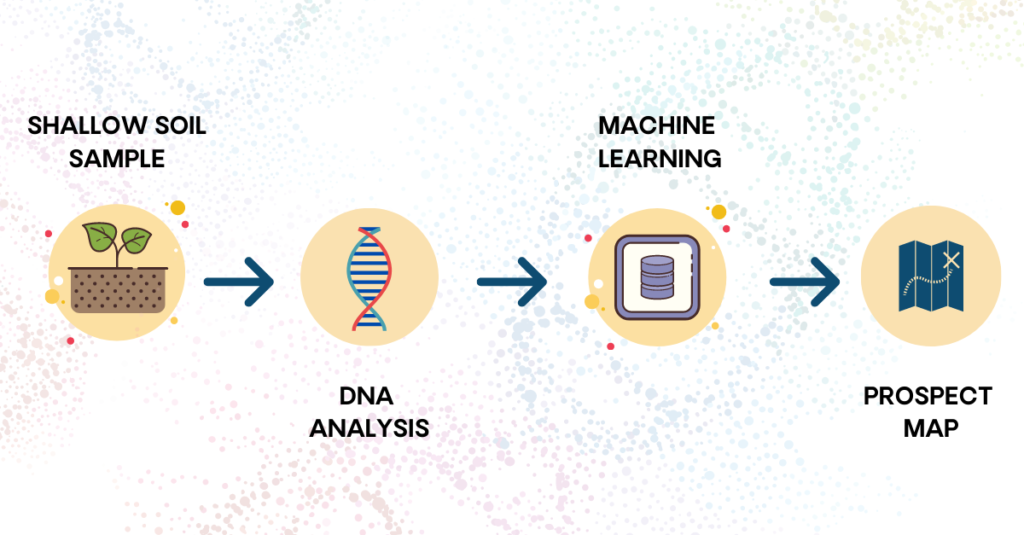
Building our training database to improve prediction accuracy
At the beginning of this Argentina project, we built our training database by taking and adding local samples from areas where oil and gas were known to be present. We typically combine this local data with our existing database of DNA fingerprints to improve prediction accuracy. This is because the microbial DNA varies a little depending on the soil or seabed conditions, the country, the climate, etc.
In order to enhance our existing dataset for this case, we additionally executed a second proof of technology project in the USA—described in detail in a follow-up article coming later. This added labeled unconventional data samples (which are known status, high versus low producing) to our database, and makes the entire model more robust.
In essence, we wanted to predict unconventional fields in Argentina without having unconventional Argentina data samples. The USA project, and its resulting data, enabled us to obtain this information from unconventional fields in Texas and North Dakota.
Sampling details for our Argentinian pilot
In this pilot, 1620 samples for DNA profiling were taken covering a geographical area of 2000 km. Of these samples, 1100 samples were taken at locations with known hydrocarbon presence. The samples were taken in five different sets, each representing a certain type of subsurface condition:
- Outside the basin area to avoid the influence of source rocks (true negative)
- Active source rock, a shallow oil field under pressure (true positive)
- Active source rock and pressured deep gas fields (true positive)
- The unconventional play of the Vaca Muerta area
- The remaining area with a number of depleted fields.
To check the validity of Biodentify’s technique, 300 samples were blinded (100 from sets A-B-C) after sample taking, leaving 800 known samples left for us to ‘train’ the model with; these 300 blinded samples had the labels taken off by the operator. The aim of blinding samples was to prove our prediction accuracy—with the results cross-checked and verified at the end.
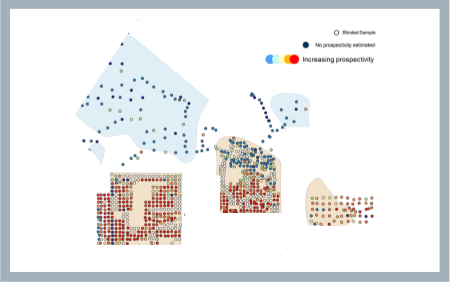
Anonymized map showing fieldwork area and prospectivity; area A is located further out and not included in this map.
Extra models tested within this Argentinian pilot
In addition to the above, an extra model was created to test if we could distinguish shallow oil (set B), from deep gas accumulations (set C). Take note that it is not possible to predict a priori, but if one of the two is present and known the other can be identified.
Finally, the ‘exportability’ of the method was tested to see if we could train a model from one location to predict an entirely new location, without the need to first collect local samples from known (oil and gas, or dry) locations. To do this, our USA model—without local Argentinian data—was used to predict prospectivity of the Argentina Vaca Muerta study area.
Argentina Vaca Muerta area pilot results and conclusions
After analyzing the Argentinian samples in our labs and building a training model from known samples, a productivity estimate was made for the 300 blinded samples. To do this we used our Triple Loop Machine Learning approach, learn more about this on our website or email us to request our detailed white paper.
The main result was a correct prediction for 97% of the blinded samples—that either we were above an oil or gas field, or in a dry area. In more detail, we predicted 97 of the 100 oil samples as hydrocarbon samples, 97 of the 100 gas samples as hydrocarbon samples, and 98 of the 100 dry samples, as dry.

Secondly, the model between deep and shallow oil and gas was forecast at 87% accuracy. This, put simply, means our technology can actually distinguish between whether subsurface hydrocarbons are oil or gas reserves.
Thirdly, results for exportability were also very encouraging. Prediction accuracy of 83% was achieved through using only our USA database and predicting the full set of Argentina samples—200 oil and gas blinded samples versus 100 dry samples. Training data, from a different continent, was able to predict locations more than 8,400 km away.
We can conclude that our methodology does, as applied here in this Argentina pilot and proof of technology, before drilling and without knowing anything about the subsurface conditions, extremely accurately predict the presence of hydrocarbons in the subsurface.
We believe these results are sufficiently interesting for other major oil and gas operators to apply this technology for their own projects, minimizing risk, maximizing returns and saving money.
To find out more, do not hesitate to get in touch via our LinkedIn profile or website.
About Biodentify
Biodentify was founded as a spin-out from Dutch R&D group TNO in December 2014. TNO is a 3000+ R&D organization and the largest microbiological research group in the Netherlands. Biodentify is owned and managed by 3 partners with extensive entrepreneurial experience bringing innovative new technologies to market in the Oil & Gas industry. The company has developed a novel and patented technology, predicting prospectivity before drilling, with > 70% accuracy, based on microbial DNA analysis of shallow soil or seabed samples through unique machine learning models. Biodentify was named the #58 most innovative company in 2019 by the KvK (Chamber of Commerce).